如果你的阿里云OSS Bucket 储存的内容非常大,非常多,取回下载困难,那么这个py脚本能非常好的帮助你解决问题!
脚本采用5线程(可根据情况修改),下载速度嘎嘎快!自动对比本地文件和OSS文件,如果相同则跳过下载,避免重复下载,浪费流量!
由于阿里云的对象储存价格太高,所以我想把阿里云里储存的内容下载回本地,但如果你储存的内容非常多,使用阿里云官方提供的oss-browser工具或OSSFTP工具下载,都会非常慢,而且在文件很多时会报错,所以开发了这个Python脚本,从阿里云OSS下载回数据!
(不知道为什么阿里云那么大的公司,在针对文件很多很大时下载回本地,连个正经的下载回数据的工具都没有,上传数据到非常容易,原因不言而喻)
1.首选给你的 Bucket 授权
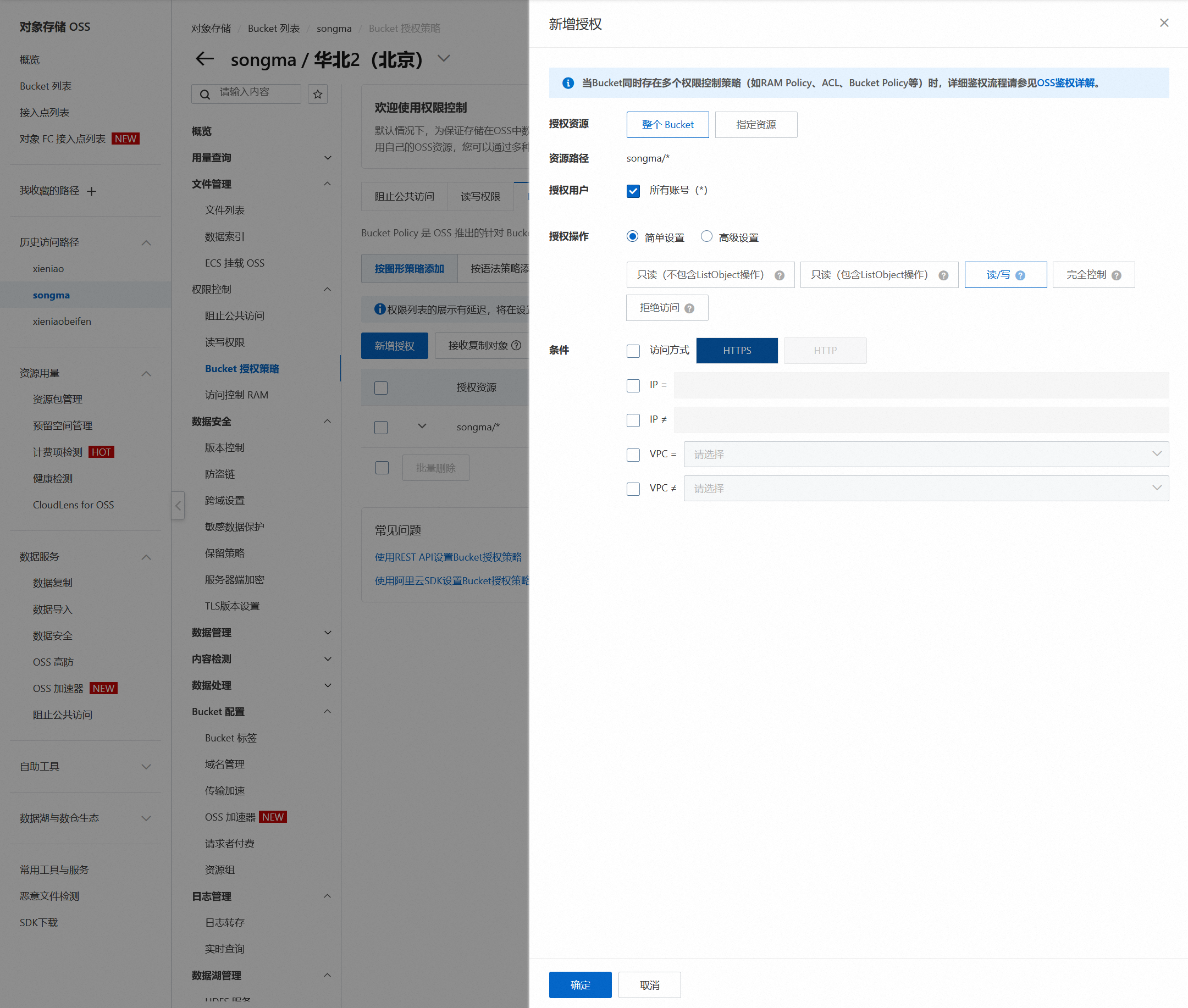
2.Python脚本代码
import oss2
import os
import hashlib
from concurrent.futures import ThreadPoolExecutor
# 配置阿里云OSS账号和桶的信息
access_key_id = '你的'
access_key_secret = '你的'
endpoint = '外网访问网址'
bucket_name = 'Bucket 名称'
# 本地下载目录(根据你要下载到什么目录修改)
local_dir = r'G:\web\songma'
# 初始化OSS服务
auth = oss2.Auth(access_key_id, access_key_secret)
bucket = oss2.Bucket(auth, endpoint, bucket_name)
# 计算文件的md5值,用于判断文件是否已经存在
def file_md5(filename):
if not os.path.isfile(filename):
return None
hash_md5 = hashlib.md5()
with open(filename, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
# 获取本地文件大小
def get_local_file_size(filepath):
if os.path.exists(filepath):
return os.path.getsize(filepath)
return None
# 下载文件
def download_file(oss_file, local_file):
print(f"正在下载:{oss_file} -> {local_file}")
bucket.get_object_to_file(oss_file, local_file)
print(f"下载完成:{local_file}")
# 处理单个文件的下载逻辑
def process_download(obj, oss_prefix, local_dir):
oss_file_path = obj.key
if oss_file_path.endswith('/'):
return # 跳过目录
local_file_path = os.path.join(local_dir, os.path.relpath(oss_file_path, oss_prefix))
# 确保本地子目录存在
local_file_dir = os.path.dirname(local_file_path)
if not os.path.exists(local_file_dir):
os.makedirs(local_file_dir)
# 获取远程文件的大小
remote_file_size = obj.size
# 检查本地文件的大小
local_file_size = get_local_file_size(local_file_path)
# 如果文件存在且大小相同,跳过下载
if local_file_size is not None and local_file_size == remote_file_size:
print(f"跳过已存在且大小相同的文件:{local_file_path}")
return
# 下载文件
download_file(oss_file_path, local_file_path)
# 并行下载文件
def download_all_files_from_oss(bucket, oss_prefix, local_dir, max_workers=5):
# 确保本地目录存在
if not os.path.exists(local_dir):
os.makedirs(local_dir)
# 使用线程池进行并行下载
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = []
for obj in oss2.ObjectIterator(bucket, prefix=oss_prefix):
futures.append(executor.submit(process_download, obj, oss_prefix, local_dir))
# 等待所有任务完成
for future in futures:
future.result()
if __name__ == '__main__':
# 并行下载 songma/ 目录下的所有文件到 G:\web\songma,使用 5 个线程并行下载(根据你自己的需要修改需要下载那个目录)
download_all_files_from_oss(bucket, 'songma/', local_dir, max_workers=5)
3.在运行脚本前,请先给你的Python安装OSS2
pip install oss2
如果对你有用,记得评论点赞,谢谢!
© 版权声明
特别提醒: 内容为用户自行发布,如有侵权,请联系我们管理员删除,邮箱:mail@xieniao.com ,在收到您的邮件后我们会在3个工作日内处理。
相关文章
暂无评论...
XieNiao 血鸟导航,集网址、资源、资讯于一体的定制化导航主题,简约优雅的设计风格,自定义网址的用户功能,自定义主页,欢迎您的体验

 赣公网安备36020002000448号
赣公网安备36020002000448号